Collations / Input / Presentation

Collation/Input/Presentation
Michael G. Sargent
My dream of electronic textual presentation is of a set of multivalent entities floating in cyberspace, each one representing a text, or a version of a text, or a manuscript, or a language, or a scribe, or a provenance, or … whatever. The reader could dock on any level of one of these arcologies of information and it would display the multiplicity of forms that it comprises. The reader could, for example, choose the default form of the text––the ‘edition’––constructed according to the judgement of the editor (or editors) who had worked through all of the various forms of the text, or select a different form of the text according to his or her own particular interest. All readings of all versions of the text would be presented as an apparatus, and the variants would rearrange themselves to reflect the reader’s choice of base-text. I am not computer-literate enough to accomplish such an edition: I am only capable of approaching aspects of it in print-publishable form, but I wonder how such a work might be accomplished.
In my limited experience, when I describe such a fantasy to an IT-person, he stops me partway through and says, ‘Oh, yes: I’ve got something that will do just what you want,’ and pulls off of the shelf something that was designed for an entirely different purpose, and which in fact does not do what I want; I have to change what I want to make it conform to what the software will do. I suspect that we will need to design the software that does accomplish what we envisage, and I believe that the most useful role for me to play is to make suggestions based on my own pencil-and-paper experience collating and editing texts for things that we need to keep in mind.
In 1992, I produced an edition of Nicholas Love’s Mirror of the Blessed Life of Jesus Christ, the primary Middle English version of the pseudo-Bonaventuran Meditationes vitae Christi, for a series of best-text editions published by Garland. Pushing the critical limits of the series, I collated my base-manuscript, Cambridge University Library Add. MS 6578 (which belonged to Mount Grace Charterhouse in Yorkshire and had been written during Love’s priorate there in the early fifteenth century) with another, CUL MS Add. 6686, which was nearly identical in text and dialect. I also collated specimen passages from six points in the text, totalling some 2,300 words (out of somewhat more than 100,000) for all surviving originally complete manuscripts. This preliminary collation demonstrated three primary versions of the text, designated ⍺, β, and ɣ, distinguishable in several major variations of a paragraph or more in length, plus a number of minor variants throughout. The collation also demonstrated two or three sub-versions of each of the three primary versions.
Presented by the University of Exeter Press with the opportunity to produce a full critical edition of Love’s Mirror, published in 2005, I produced a complete collation of all manuscripts written in the first quarter of the fifteenth century, including at least the three earliest manuscripts of each variational group––a total of twenty-seven manuscripts. All later manuscripts were also collated, but only for those readings that occurred in the first twenty-seven. What I termed the ‘noise level’ of random readings that might demonstrate the affiliations among the later manuscripts of the various sub-groups could thus be limited while the difference among the affiliational groups and sub-groups would stand out more clearly.
––Slide 2: Nicholas Love stemma––

In this graphic presentation, each surviving manuscript of each version is listed in approximate chronological order of production. Some of the manuscripts are listed more than once, either because they represent conflations of different versions of the text, or they change exemplar for distinct sections of the text. As I have noted elsewhere, such a presentation of information is limited by the two-dimensional, flat page format characteristic of the print medium.
––Slide 3: Nicholas Love Rhizome––
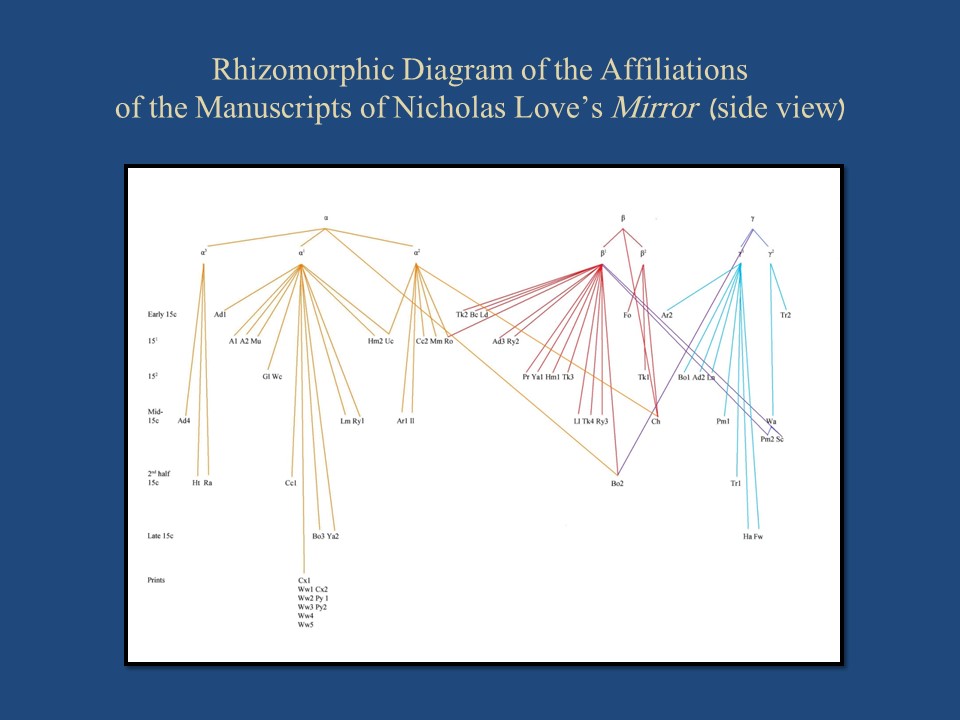
The same information can also be presented in a form compatible with three dimensions (although here still in two dimensions). Imagine this flat page as a cyclinder, with the affiliational group sigla ⍺, β, and ɣ as points on the circle that it inscribes. The lower-level subgroup sigla ⍺1-3, β1-2, and ɣ1-2 are points on further circles suspended from ⍺, β, and ɣ, and the various individual manuscript sigla are points suspended from the subgroup sigla in the same way. The result is seven lower-level cones of diffusion comprising the forty-eight surviving manuscripts collated, suspended from three higher cones representing the ⍺, β, and ɣ versions of the text. The omega-point at the top of the previous chart, representing the hypothetical ur-text, has been deleted: I no longer believe that there was such a single ur-text.
This simple graphic representation was generated by hand, and the individual manuscripts are presented as equidistant from each other, suspended further down the page according to the relative chronology of their production. In a more sophisticated, three-dimensional, cybernetic version, the group sigla ⍺, β, and ɣ, the subgroup sigla ⍺1-3, β1-2, and ɣ1-2, and the individual manuscript sigla would be better represented as separated from each other by the Levenshtein distance of their variation.[1] In a medieval text without standard spelling, the editor would have to decide what to count as a unit of variation: whether to count, for example, variant readings––allographs––that might have lexical or morpho-syntactic significance, such as a northern-dialect third person singular present tense verb form ending in /-Es/ rather than /-Eþ/ but mistaken by a later scribe for the plural form of a cognate noun, or a southern dialect third person singular present tense verb form ending in /-Eþ/ mistaken by a northern scribe for a simple past-tense form transcribed as /-Et/––and the remainder of the text changed to past tense in order to conform. (Both of these things occur in texts that I have collated).
Chronology need not be presented as a spatial axis at all (as it is presented vertically in this chart), but could be incorporated by building a temporal component into the presentation itself. In a timed presentation, for example, new manuscripts and versions of the text could blink into existence at appropriate times, and would normally remain from that point on, since we can usually assume for late medieval manuscript books (as we cannot for modern prints) that they continued to be read––and even copied––for some time after their production.
In my fantasy, a reader ‘landing’ on any manuscript sigil should be able to access a text based on that manuscript, with all others relegated to an apparatus that could be accessed by highlighting a word or phrase and clicking on it. In terms of input, this would require a complete transcription of each manuscript of the text, and software capable of ‘flipping’ the apparatus depending on the choice of base-text. Individual readings would have to be coded for whether they represent simple spelling and dialectal morphological variants, which are usually––but not always––significant in consideration of textual affiliation. The apparatus should also be capable of being ‘scoped’ to present, for example, an apparatus of ⍺-manuscript variants, or of ⍺1 manucript variants, should the reader choose to focus in on variations at the group or sub-group level. Landing on one of the affiliational group sigla would trigger an editorial form of the text, should the editor chose to provide one. Again, I do not envisage the necessity of an omega-form of the text, except as a point from which to trigger comparison of the affiliational group variations. This is, after all, an un-edition. Nor does the graphic representation need to be presented as descending––a relict of the pedigree orientation that Joseph Bédier noted a century ago as a flaw in the conceptualization of recension. In fact, if the graphic representation were conceptualized in three dimensions, the ⍺, β, ɣ, ⍺1-3, β1-2, and ɣ1-2 points could all be presented as the centre points of global variational clusters of texts.
More recently, I have been working to complete the critical edition of Walter Hilton’s Scale of Perfection, a text in two books written separately in the last decades of the fourteenth century. Book I circulated for some time without Book II: among the fifty-two surviving manuscripts in English (there was also a contemporary Latin translation), seventeen originally comprised complete copies of Book I alone, twenty-three comprised both books (of which two at least originally contained only the first book), two comprise Book II alone, and one comprises an English Book I and a Latin Book II; eleven manuscripts present fragments or extracts. In the latter half of the twentieth century, A.J. Bliss and S.S. Hussey came close to producing recensionist critical editions of the Scale (Bliss for Book I and Hussey for Book II), but flaws and gaps in their work have required at least a degree of re-collation and reconceptualization. I collated the whole of Scale II anew for an edition published by the Early English Text Society in 2017 (Hussey’s original collation had gone missing over the years). The results of the tabulation of the variants did not produce the typical recensionist cascade of bifurcation, but a rhizome with seven English branches (ranging from one to fifteen manuscript or print witnesses), plus the Latin.
––Slide 4: Scale II Rhizome––

I am presently in process of reducing Bliss’ collations of Scale II (which seem to be appropriately accurate, but which I will still test) to a critical apparatus that will then be tabulated to produce a final description of the affiliations of the text.
––Slide 5: Bliss collations––

My own observations in the process of working through the collations (I am nearly two-thirds of the way through), Bliss’ textual discussions and those of Rosemary (Birts) Dorward before him point in the direction of a pattern of affiliations somewhat more complex than that for Scale II (as should be expected).
––Slide 6: Scale I and II Rhizome Hypothesis 1––
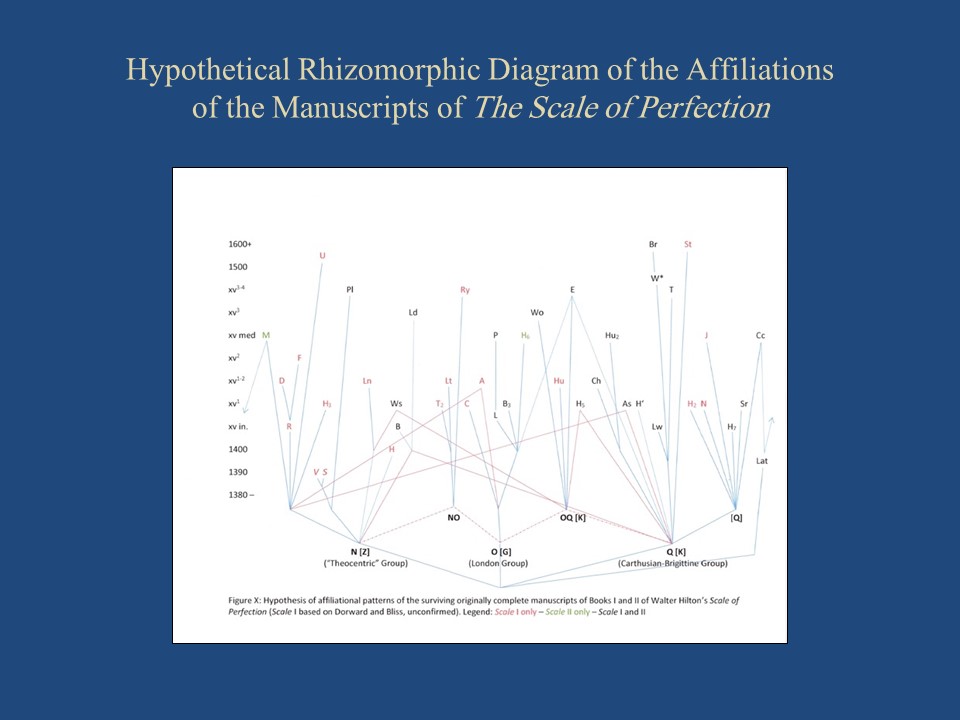
This presentation is a bottom-up version of the same kind of graphic representation that you have already seen for the text of Nicholas Love’s Mirror.
––Slide 7: Scale I and II Rhizome Hypothesis 3––
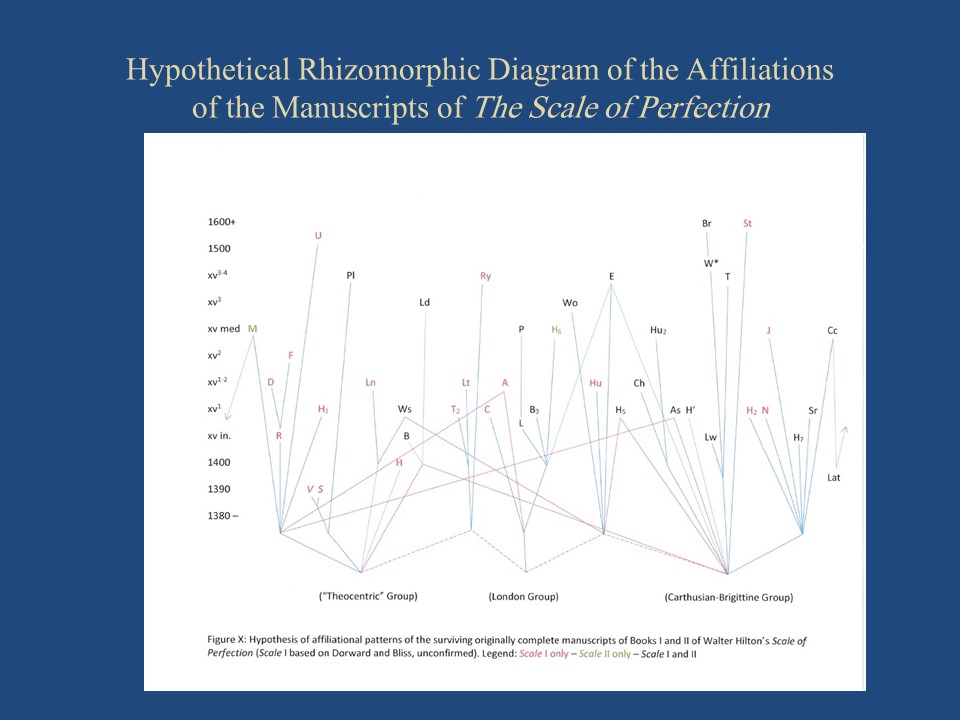
Again, imagine this pattern projected onto a cylinder, with each of the affiliational sub-groups surrounded by a separate cone of diffusion of the text––and again, without an ur-text omega point. This presentation will have to be revised when I have completed the tabulation of textual variants for Book II.
A text surviving in more than one language, like Mandeville’s Travels, would add a further set of complications even at the level of collation. Marguerite Porete’s Mirouer des simples âmes anienties, for example, a book originally circulating in Hainault, burned together with its author in Paris in 1310, survives in a single complete manuscript in Françien dialect written at the turn of the sixteenth century, a late fourteenth-century extract in the author’s original Picard, a flawed English translation made from the French, a literal Latin translation made from that, a Latin translation made from the original French that seems to have circulated primarily in northern Italy, and two recensions of an Italian version made from that. In an attempt to compare these various versions closely, I produced a collation of the two-chaper passage that survives in all versions, not at the word-by-word level, but at the level of comparable short phrases.[2]
––Slide 8: Marguerite Porete collation––
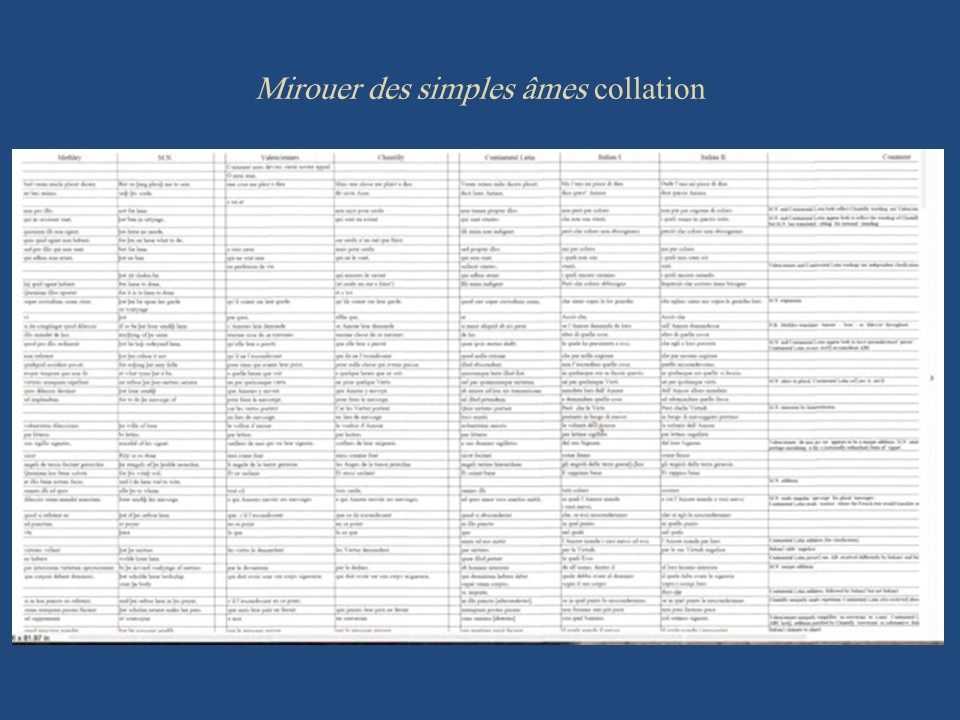
Since the English version and its Latin translation on the one hand, and the continental European Latin version and the Italian translation based on it, derive from the French, I have positioned the two versions of the French text in the middle, with the others on either side. There is a further column of comments at the far right.
The textual conclusion that I drew from this collation––contrary to that of others working with this text––is that neither the French, the English, nor the continental European Latin version is uniformly superior as a representative of what Marguerite may originally have written: the study of this text demands attention to all of the various versions. This level of textual comparison needs further investigation.
What I have presented today is a set of thought-experiments drawn from the development of my own thoughts over time on how we might better conceptualize visually the relations––particulary, for me, the textual affiliations––of the medieval manuscripts that we study. I hope you find them useful.
[1] In computational linguistics, Levenshtein distince is the measure of the number of changes required in order to turn one string into another. The strings ‘kitten’ and ‘letter’, for example, have a Levenschtain distance of three: the initial ‘k’ must be changed to an ‘l’, the ‘i’ to an ‘e’, and the ‘n’ to an ‘r’.
[2] The full collation can be found on my Academia.edu page.